
Generative AI and Large Language Models Intersection
Understanding the Foundations: The Transformer


Introduction
In 2017, the paper, Attention is All You Need, laid out all of the fairly complex data processes that will happen inside the transformer architecture and beyond transformers, There's a second major topic, that we are going to discuss in this blog the Generative AI project Lifecycle. The Generative AI Project Lifecycle will help you plan out how to think about building your own Generative AI project and walk you through the individual stages and decisions you have to make when you're developing Generative AI applications.
The first thing you have to decide is whether you're taking a foundation model off the shelf or you're actually pre-training your own model and then as a follow-up, whether you want to fine-tune and customize that model maybe for your specific data there might be use cases where you need the model to be very comprehensive and able to generalize to a lot of different tasks and there might be use cases where you're just optimizing for a single-use case, and you can potentially work with a smaller model and achieve similar or even very good results. One of the really surprising things for some people to learn is that you can actually use quite small models and still get quite a lot of capability out of them.
Generative AI & LLMs
Generative AI is a subset of traditional machine learning and the machine learning models that underpin generative AI have learned these abilities by finding statistical patterns in massive datasets of content that was originally generated by humans. Large language models have been trained on trillions of words over many weeks and months and with large amounts of computing power. The more parameters a model has, the more memory, and as it turns out, the more sophisticated the tasks it can perform.
The way you interact with language models is quite different than other machine learning and programming paradigms. In those cases, you write computer code with formalized syntax to interact with libraries and APIs. In contrast, large language models can take natural language or human written instructions and perform tasks much as a human would. The text that you pass to an LLM is known as a prompt. The space or memory that is available to the prompt is called the context window, and this is typically large enough for a few thousand words but differs from model to model. The output of the model is called a completion, and the act of using the model to generate text is known as inference.
LLM use cases
Next word prediction is the base concept behind several different capabilities, starting with a basic chatbot. However, you can use this conceptually simple technique for a variety of other tasks within text generation.
For example, ask a model to write an essay based on a prompt, to summarize conversations where you provide the dialogue as part of your prompt.
You can use models for a variety of translation tasks from traditional translation between two different languages, to translating natural language to machine code. You can use LLMs to carry out smaller, focused tasks like information retrieval. The understanding of knowledge encoded in the model's parameters allows it to correctly carry out this task and return the requested information to you.
Developers have discovered that as the scale of foundation models grows from hundreds of millions of parameters to billions, even hundreds of billions, the subjective understanding of language that a model possesses also increases. This language understanding stored within the parameters of the model is what processes, reasons, and ultimately solves the tasks you give it, but it's also true that smaller models can be fine-tuned to perform well on specific focused tasks.
Text generation before Transformers
Generative algorithms are not new. Previous generations of language models made use of an architecture called Recurrent Neural Networks or RNNs. RNNs while powerful for their time, were limited by the amount of compute and memory needed to perform well at generative tasks. To successfully predict the next word, models need to see more than just the previous few words. Models need to have an understanding of the whole sentence or even the whole document.
For example, an RNN is carrying out a simple next-word prediction generative task. With just one previous word seen by the model, the prediction can't be very good. As you scale the RNN implementation to be able to see more of the preceding words in the text, you have to significantly scale the resources that the model uses. As for the prediction, the model will fail. Even though you scale the model, it still hasn't seen enough of the input to make a good prediction.
The problem is that language is complex. In many languages, one word can have multiple meanings. They are called homonyms. It's only with the context of the sentence that we can see what it actually means. Words within a sentence structure can be ambiguous or have what we might call Syntactic Ambiguity.
For example, "The teacher taught the students with the book." Did the teacher teach using the book or did the student have the book, or was it both? How can an algorithm make sense of human language if sometimes we can't?
Well, the publication of the paper, Attention is All You Need, from Google, changed everything. The transformer architecture had arrived. It can be scaled efficiently to use multi-core GPUs, it can parallel process input data, making use of much larger training datasets, and crucially, it's able to learn to pay attention to the meaning of the words it's processing.
Transformers architecture
The transformer architecture dramatically improved the performance of natural language tasks over the earlier generation of RNNs and led to an explosion in regenerative capability. The power of transformer architecture lies in its ability to learn the relevance and context of all of the words in a sentence.
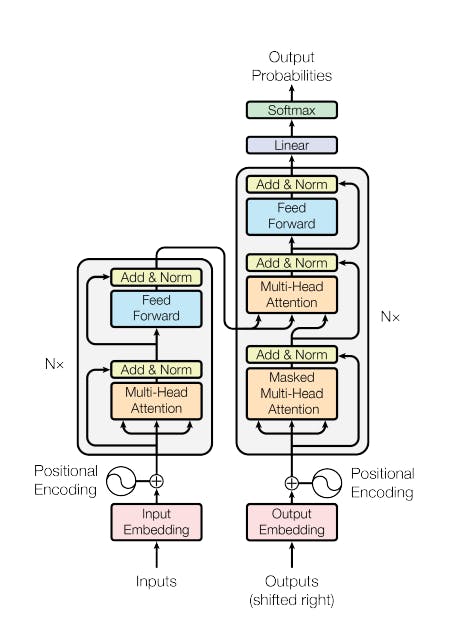
The transformer architecture is split into two distinct parts, the encoder and the decoder. These components work in conjunction with each other and they share several similarities. The machine-learning models are just big statistical calculators and they work with numbers, not words. So before passing texts into the model to process, you must first tokenize the words. Simply put, this converts the words into numbers, with each number representing a position in a dictionary of all the possible words that the model can work with. There are multiple tokenization methods.
For example, token IDs matching two complete words, or using token IDs to represent parts of words. Note, that once you've selected a tokenizer to train the model, you must use the same tokenizer when you generate text.
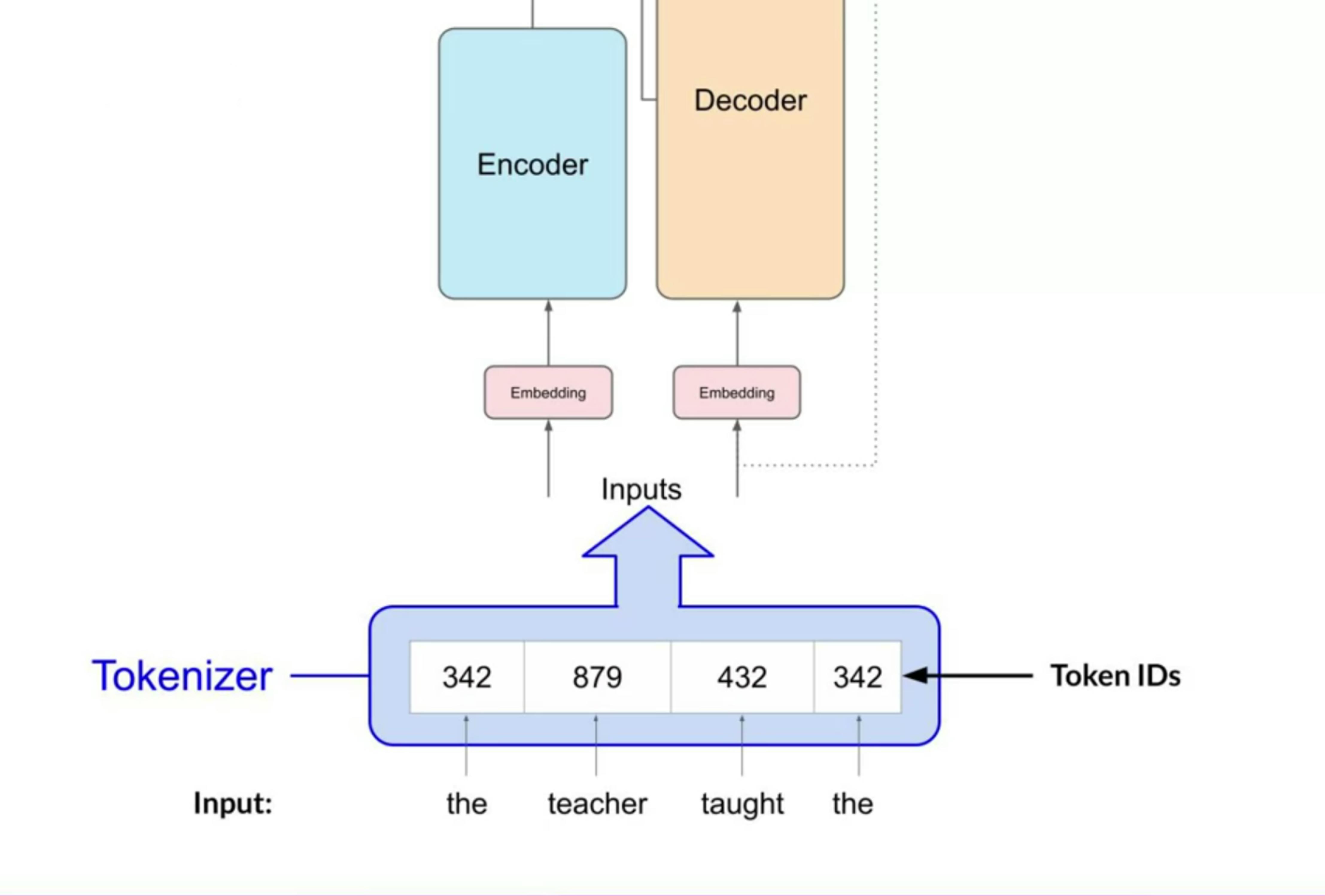
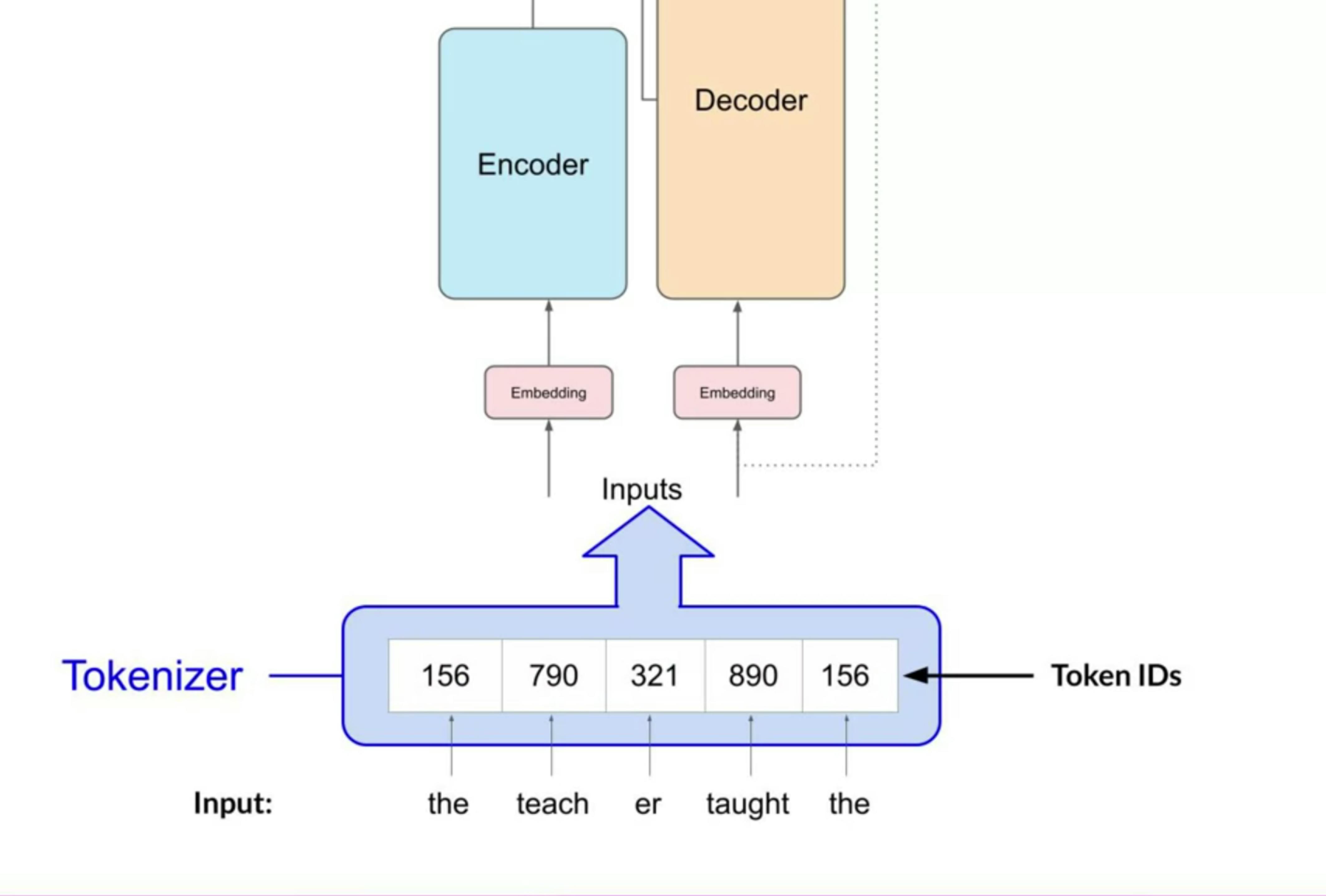
Now that your input is represented as numbers, you can pass it to the embedding layer. This layer is a trainable vector embedding space, a high-dimensional space where each token is represented as a vector and occupies a unique location within that space. Each token ID in the vocabulary is matched to a multi-dimensional vector, and the intuition is that these vectors learn to encode the meaning and context of individual tokens in the input sequence. In the original transformer paper, the vector size was 512. For simplicity, if you imagine a vector size of just three, you could plot the words into three-dimensional space and see the relationships between those words.

You can see now how you can relate words that are located close to each other in the embedding space, and how you can calculate the distance between the words as an angle, which gives the model the ability to mathematically understand language. As you add the token vectors into the base of the encoder or the decoder, you also add positional encoding. The model processes each of the input tokens in parallel. So by adding the positional encoding, you preserve the information about the word order and don't lose the relevance of the position of the word in the sentence. Once you've summed the input tokens and the positional encodings, you pass the resulting vectors to the self-attention layer. Here, the model analyzes the relationships between the tokens in your input sequence. As you read earlier, this allows the model to attend to different parts of the input sequence to better capture the contextual dependencies between the words. The self-attention weights that are learned during training and stored in these layers reflect the importance of each word in that input sequence to all other words in the sequence. But this does not happen just once, the transformer architecture has multi-headed self-attention. This means that multiple sets of self-attention weights or heads are learned in parallel independently of each other. The number of attention heads included in the attention layer varies from model to model, but numbers in the range of 12-100 are common. The intuition here is that each self-attention head will learn a different aspect of language.
For example, one head may see the relationship between the people entities in our sentence. Whilst another head may focus on the activity of the sentence. Whilst yet another head may focus on some other properties such as if the words rhyme. It's important to note that you don't dictate ahead of time what aspects of language the attention heads will learn. The weights of each head are randomly initialized and given sufficient training data and time, each will learn different aspects of language. While some attention maps are easy to interpret, others may not be.
Now that all of the attention weights have been applied to your input data, the output is processed through a fully connected feed-forward network. The output of this layer is a vector of logits proportional to the probability score for each and every token in the tokenizer dictionary. You can then pass these logits to a final softmax layer, where they are normalized into a probability score for each word. This output includes a probability for every single word in the vocabulary, so there are likely to be thousands of scores here. One single token will have a score higher than the rest. This is the most likely predicted token.
Generating text with transformers
The overall prediction process works from end to end through a simple example. In this example, you'll look at a translation task or a sequence-to-sequence task, which incidentally was the original objective of the transformer architecture designers. You'll use a transformer model to translate the French phrase into English. First, you'll tokenize the input words using this same tokenizer that was used to train the network. These tokens are then added to the input on the encoder side of the network, passed through the embedding layer, and then fed into the multi-headed attention layers. The outputs of the multi-headed attention layers are fed through a feed-forward network to the output of the encoder. At this point, the data that leaves the encoder is a deep representation of the structure and meaning of the input sequence. This representation is inserted into the middle of the decoder to influence the decoder's self-attention mechanisms. Next, a start of sequence token is added to the input of the decoder. This triggers the decoder to predict the next token, which it does base on the contextual understanding that it's being provided by the encoder. The output of the decoder's self-attention layers gets passed through the decoder feed-forward network and through a final softmax output layer. At this point, we have our first token. You'll continue this loop, passing the output token back to the input to trigger the generation of the next token, until the model predicts an end-of-sequence token. At this point, the final sequence of tokens can be detokenized into words, and you have your output. The complete transformer architecture consists of encoder and decoder components. The encoder encodes input sequences into a deep representation of the structure and meaning of the input. The decoder, working from input token triggers, uses the encoder's contextual understanding to generate new tokens. It does this in a loop until some stop condition has been reached.
While the translation example we explored here used both the encoder and decoder parts of the transformer, you can split these components apart for variations of the architecture. Encoder-only models also work as sequence-to-sequence models, but without further modification, the input sequence and the output sequence or the same length. Their use is less common these days, but by adding additional layers to the architecture, you can train encoder-only models to perform classification tasks such as sentiment analysis, BERT is an example of an encoder-only model. Encoder-decoder models, as you've seen, perform well on sequence-to-sequence tasks such as translation, where the input sequence and the output sequence can be different lengths. You can also scale and train this type of model to perform generation tasks. Decoder-only models are some of the most commonly used today. Again, as they have scaled, their capabilities have grown. These models can now generalize to most tasks. Popular decoder-only models include the GPT family of models, BLOOM, Jurassic, LLaMA, and many more.
Generative configuration: Parameter for Inference
Some of the methods and associated configuration parameters that we can use to influence the way that the model makes the final decision about next-word generation. If you've used LLMs in playgrounds such as on the Hugging Face website or an AWS, you might have been presented with controls like these to adjust how the LLM behaves. Each model exposes a set of configuration parameters that can influence the model's output during inference. Note that these are different than the training parameters which are learned during training time. Instead, these configuration parameters are invoked at inference time and give you control over things like the maximum number of tokens in the completion, and how creative the output is. Max new tokens are probably the simplest of these parameters, and you can use them to limit the number of tokens that the model will generate. You can think of this as putting a cap on the number of times the model will go through the selection process. Remember it's max new tokens, not a hard number of new tokens generated. The output from the transformer's softmax layer is a probability distribution across the entire dictionary of words that the model uses. Most large language models by default will operate with so-called greedy decoding. This is the simplest form of next-word prediction, where the model will always choose the word with the highest probability. This method can work very well for short generations but is susceptible to repeated words or repeated sequences of words. If you want to generate text that's more natural, more creative and avoids repeating words, you need to use some other controls. Random sampling is the easiest way to introduce some variability. Instead of selecting the most probable word every time with random sampling, the model chooses an output word at random using the probability distribution to weight the selection. By using this sampling technique, we reduce the likelihood that words will be repeated. However, depending on the setting, there is a possibility that the output may be too creative, producing words that cause the generation to wander off into topics or words that just don't make sense. Note that in some implementations, you may need to disable greedy and enable random sampling explicitly.

Top k and top p sampling techniques help limit random sampling and increase the chance that the output will be sensible. Two Settings, top p, and top k are sampling techniques that we can use to help limit the random sampling and increase the chance that the output will be sensible. To limit the options while still allowing some variability, you can specify a top k value which instructs the model to choose from only the k tokens with the highest probability. This method can help the model have some randomness while preventing the selection of highly improbable completion words. This in turn makes your text generation more likely to sound reasonable and to make sense. Alternatively, you can use the top p setting to limit the random sampling to the predictions whose combined probabilities do not exceed p.
With top k, you specify the number of tokens to randomly choose from, and with top p, you specify the total probability that you want the model to choose from. One more parameter that you can use to control the randomness of the model output is known as temperature. This parameter influences the shape of the probability distribution that the model calculates for the next token. Broadly speaking, the higher the temperature, the higher the randomness, and the lower the temperature, the lower the randomness. The temperature value is a scaling factor that's applied within the final softmax layer of the model that impacts the shape of the probability distribution of the next token.
In contrast to the top k and top p parameters, changing the temperature alters the predictions that the model will make. If you choose a low value of temperature, say less than one, the resulting probability distribution from the softmax layer is more strongly peaked with the probability being concentrated in a smaller number of words. If you leave the temperature value equal to one, this will leave the softmax function as default and the unaltered probability distribution will be used.